Formats, metadata and paradata
Formats, metadata and paradata for field and landscape data
A reference framework for the data produced and processed across the Swedigark tutorials, covering the excavation, monuments and artefacts, and the landscape.
01 — PURPOSE
1. What this document is
This document builds on the practical experience gained while developing the Swedigarch tutorials. Through this work, we have identified the main types of data produced and processed across the different workflows, the formats used to manage them, and the metadata and paradata needed to make them understandable and reusable. The aim is not to define a fixed standard once and for all, but to provide a clear reference that can support integration and reuse across field investigation projects.
This is why the document should be understood as a living document. The technologies used in archaeological fieldwork, 3D documentation, remote sensing and data management are constantly changing. File formats, software environments, recording practices and standards also change over time. For this reason, the document needs to remain open to revision. It should be updated as the tutorials develop, as new workflows are added, and as better practices for documenting and sharing archaeological data emerge.
02 — HOW TO READ THE FRAMEWORK
2. Two kinds of format
In this document, we distinguish between two kinds of format: working formats and transfer formats. This distinction is useful because the two serve different purposes.
A working format is the format used during data processing. It is usually linked to a specific software environment. Examples include a RealityScan project, an Artec Studio project, or other project files created by the software used in a tutorial. These formats are useful while the work is being carried out, but they are often difficult to reuse outside the software that created them.
A transfer format is the format used to move data between systems, share it with others, and prepare it for long-term reuse. In this document, we use the term to refer to open or widely supported formats that are not tied to one specific programme. For each data type, the working format is the format used during processing, while the transfer format is the format that should be kept, shared and, when relevant, deposited in an archive.
This distinction is important for Swedigarch because the tutorials describe practical workflows, not only final outputs. They show how data are produced, processed and transformed. For this reason, we need to record both the software-specific formats used during the work and the more stable formats that make the data easier to understand, integrate and reuse later.
03 — THE THREE DOMAINS
3. Where the data comes from
The tutorials are organised around three areas of practice: excavation, monuments and artefacts, and landscape. These areas describe the context in which the data are produced. The data types described in the next section define the form that the data take. This distinction is useful because the same data type can appear in more than one area. For example, a 3D model can be produced during an excavation, as part of the documentation of an artefact, or in the recording of a monument.
In the excavation tutorials, the data come from the three-dimensional recording of stratigraphic units and field contexts. This includes surface and boundary models, drawn interpretations, georeferenced trenches, and geophysical results that can be interpreted in relation to the excavated ground.
In the tutorials on monuments and artefacts, the data come from the high-resolution documentation of objects, buildings and structures. These workflows include photogrammetry and structured-light scanning, as well as derived outputs such as orthographic projections, visual records and documentation reports.
In the landscape tutorials, the data come from the detection, mapping and analysis of archaeological features across larger areas. These workflows use aerial and satellite-based sensors, including UAV survey, airborne LiDAR, satellite radar and multispectral imagery. The resulting data include mapped features, classifications, spatial measurements and analytical outputs that support landscape interpretation.
04 — THE MATRIX
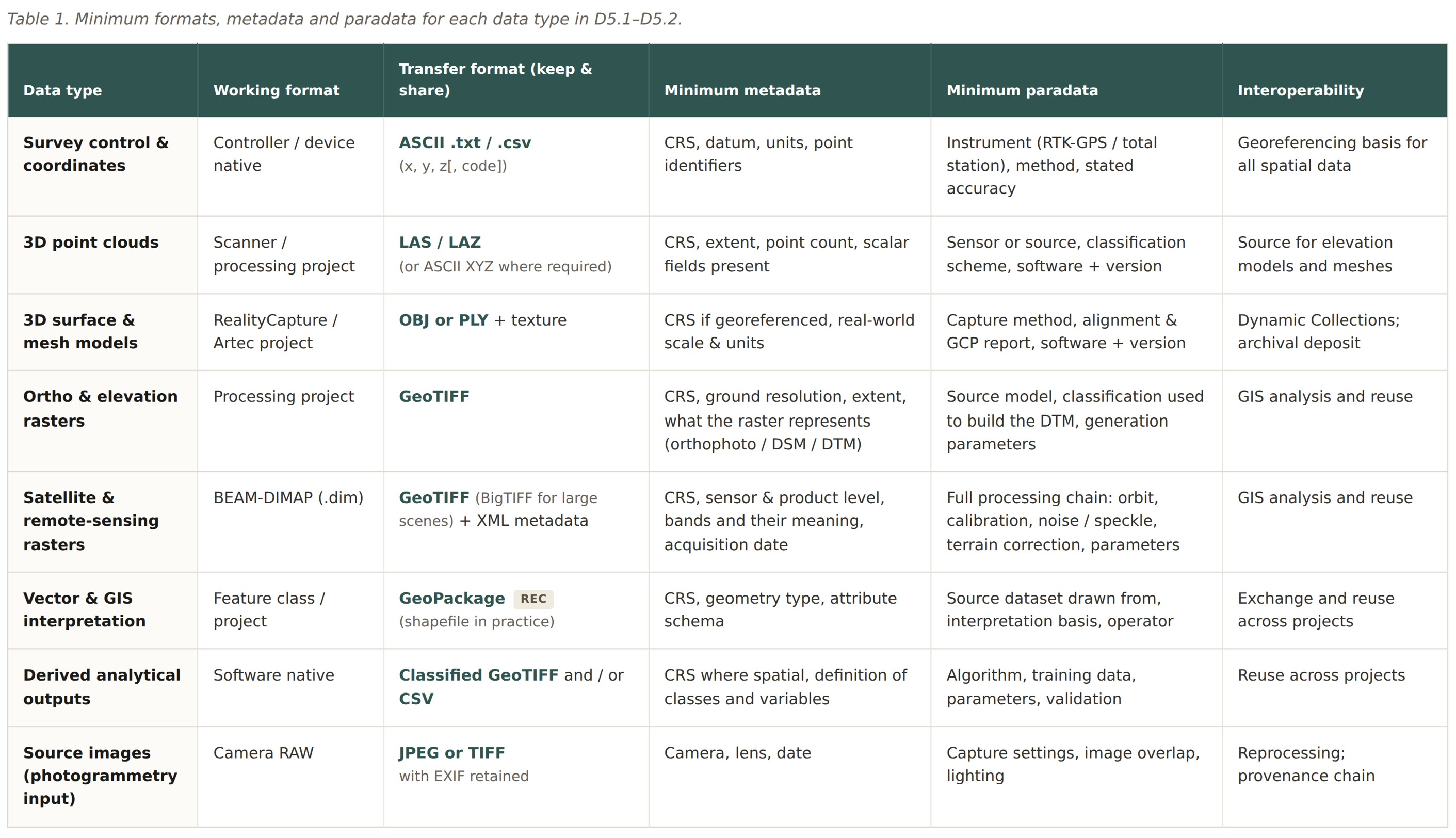
4. Formats, metadata and paradata by data type
Table 1 is the core of this document. It summarises, for each data type, the working format, the transfer format to keep and share, the minimum metadata, the minimum paradata, and the main interoperability purpose.
The table is organised by data type rather than by tutorial or technique. This keeps the structure simple and makes the requirements easier to apply across different workflows. The same type of data can appear in more than one domain. For example, point clouds can be produced from LiDAR, photogrammetry or scanning. GeoTIFF can be used for orthophotos, elevation models and satellite-derived rasters. Vector data can describe excavation interpretations, mapped landscape features or classified outputs.
This approach also helps separate current practice from recommended practice. In some cases, the format used during the tutorial workflow is not the best format for long-term reuse. For example, shapefile is still widely used in GIS practice, but GeoPackage is the recommended transfer format because it is more robust and easier to manage. Aligning tutorial outputs with these recommended formats is one of the main purposes of this document.
05 — METADATA
5. What every dataset must carry
Metadata explains what a dataset is. For spatial data, the minimum should be simple and consistent. Each dataset should state its coordinate reference system, spatial extent and units. It should also describe, in clear words, what the data represent. This is important because a later user should not have to guess whether a raster is an orthophoto, a digital surface model or a terrain model.
When a dataset is published, it should also include basic publication information: DOI, licence, author or responsible organisation, and a short description of how the files are structured. These elements make the data easier to cite, understand and reuse. Beyond this shared minimum, each data type requires a small number of additional fields, as listed in Table 1.
Where possible, this information should follow established research data practices. The Swedish National Data Service, SND, provides useful guidance on preparing data for sharing, including the need to organise data in a self-explanatory way, use widely supported and preferably open file formats, and include documentation that allows others to understand and reuse the dataset.
The aim of this document is to apply the same logic to the files produced through the Swedigarch tutorials. The data should not only be technically correct. They should also be understandable outside the original project, so that they can be integrated, cited and reused in future archaeological research.
06 — PARADATA
6. Paradata as a reproducibility layer
Paradata records how a dataset was produced. In this document, we use the term to describe the practical decisions behind the data: the instrument used, the settings selected, the software and version, the processing steps, and the parameters applied at each stage. Metadata tells us what a dataset is. Paradata tells us how it was made.
For reuse, paradata is as important as metadata. A point cloud without information about its classification scheme, or a satellite raster without its processing chain, can be opened but not properly assessed. A later user needs to know what has been corrected, filtered, classified or left unchanged. Without this information, the dataset may be technically accessible, but it is difficult to evaluate and unsafe to reuse.
This is why paradata should be understood as a reproducibility layer. It allows others to understand the choices made during data capture and processing, and to assess whether the result can be repeated, compared or integrated with other datasets.
The tutorials already contain much of this information because each tutorial documents a workflow. The purpose of this document is to make paradata an explicit requirement. For each data type, it identifies the minimum information that should travel with the data itself, not only remain in the tutorial text.
07 — INTEROPERABILITY
7. Open formats and reuse
The transfer formats listed in this document are open or widely supported formats. This is important because they are not tied to one specific programme. They can be read by different software environments, combined with other datasets, and reused after the project that created them has ended.
For each data type, the recommended transfer format in Table 1 has been selected with this purpose in mind. The aim is to make the data easier to preserve, share and integrate. A later user should be able to open and understand the dataset without needing access to the original software used during processing.
Choosing transfer formats carefully is therefore part of long-term data management. It helps keep the data usable beyond a single workflow, project or platform, and supports the broader aim of Swedigarch: making archaeological data easier to connect, interpret and reuse.